爱因互动开通了技术博客 blog.einplus.cn,欢迎大家关注。
现在一提到聊天机器人,大家就会想起各种算法模型,端到端、生成式、深度增强学习。有一种给我足够多足够好的数据,我就能用算法突破图灵测试的风范。可恨的是,就是没够多够好的数据。。相对于英文,中文可用的公开数据集少之又少。
在聊天机器人里,可用的公开对话数据就更少了,比如闲聊类的也就小黄鸡、华为微博数据,而且这些数据也都还不够好。不论是公开数据还是自己抓的各种数据,使用前的清洗都是必须的。清洗数据是个苦活,数据量大时就算投入大量人力也未必有好的产出。本文介绍爱因互动正在使用的一种数据清洗方法,我们称之为Data Purification Framework(简称DPF)。DPF是无监督的,所以基本不需要人力投入,但最终清洗效果还不错。虽然本文名为对话数据清洗,但此方法其实可以用在很多其他场景。
数据清洗框架:DPF
DPF的理念很简单,利用不靠谱的数据训练一个模型,这个模型在训练集上准确度通常都很低(如果训练集上已经完美拟合,那这个方法就不能直接用了)。用训练好的模型把最不靠谱的那些数据(预测与实际差的最远)删掉,然后利用剩下的数据训练新的模型,之后再用新模型把剩下数据里最不靠谱的一些数据删掉,如此重复,直到模型在训练集上达到较高的准确度。这时候被筛完剩下的数据可能比较少了。为了召回一些被早期模型误过滤掉的样本,我们把最新的模型应用到原始的全量数据上,这样去除最不靠谱的数据后会留下更多的数据用于接下来的迭代。之后的迭代逻辑和前面的相同,利用模型清除最不靠谱的数据,再用清洗后的新数据训练新模型。类似此方法的思想在很多地方都出现过,比如一些半监督扩充数据的场景。DPF框架图如下:
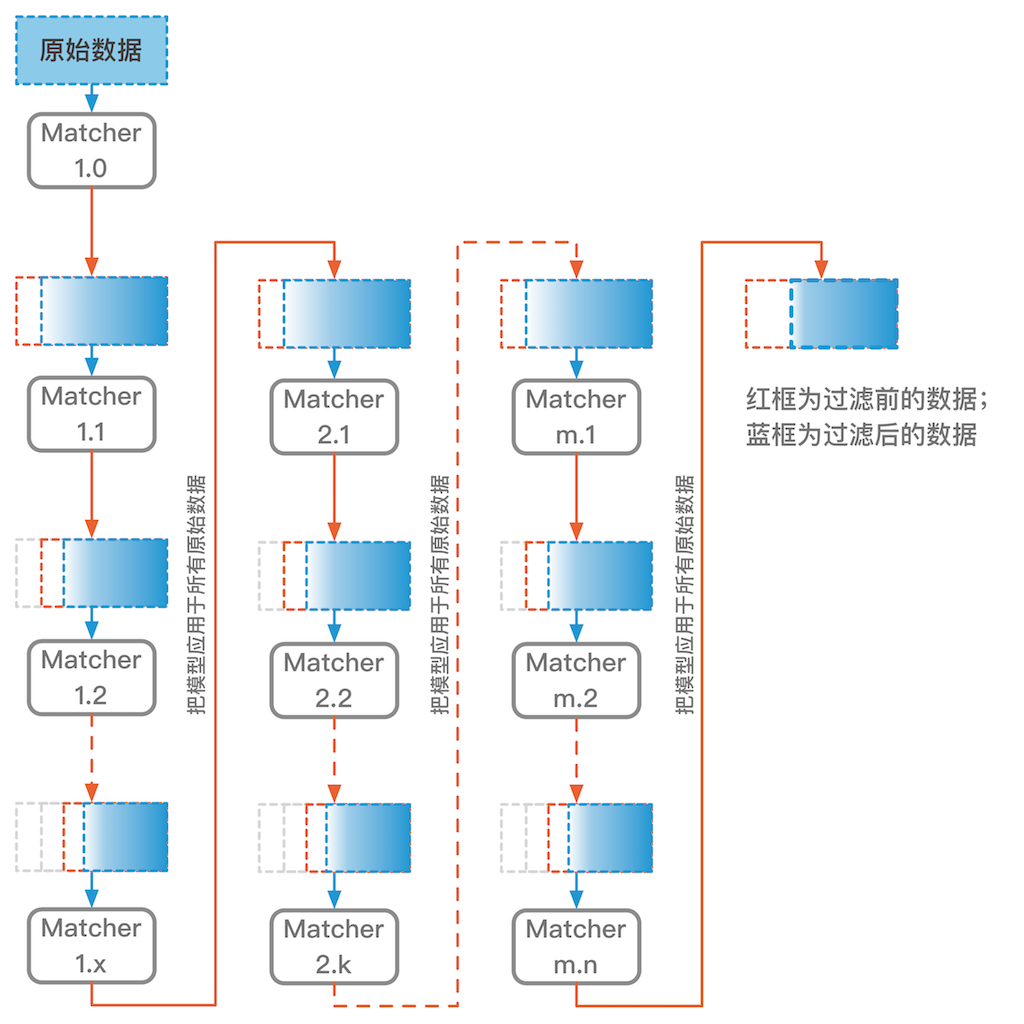
这个方法有效的一个关键是用于识别数据靠谱性的匹配模型(图中的Matcher),需要找到合适的匹配模型来统一衡量每个样本点的靠谱性。这个匹配模型不一定和数据清洗后最终被使用的模型一致。
对DPF框架图中的主要组件(下图)做个简单说明。
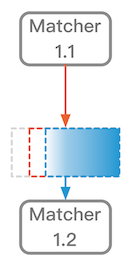
- 红色箭头连接一个模型和一个数据集,表示把此模型用于预测此数据集。这里表示使用Matcher1.1预测红框中的数据集。利用预测的匹配值,对红框中数据进行排序,清除掉匹配度最差的一部分数据,剩下的就是蓝框所表示的数据。
- 蓝色箭头连接一个数据集和一个模型,表示使用此数据集训练出此模型。这里匹配算法使用蓝框数据进行训练获得Matcher1.2。
如果这个过程都在框架的同一列,那么红框的数据就是第一个模型的训练数据(图中的红框数据是Matcher1.1的训练数据)。如果这个过程是跨列的(如框架图中Matcher1.x –> Matcher2.1),那么红框的数据就是原始的全量数据。
下面以清洗小黄鸡对话数据为例来具体说明此清洗框架的整个流程。
清洗小黄鸡对话数据
小黄鸡数据
小黄鸡数据是小黄鸡与用户的聊天qa对,包括了35w+ qa对。除了很多黄暴的样例,还有很多答案与问题压根不匹配的样例。一些样例见下图,每行中左边是问题,右边是答案。我们的初衷是使用小黄鸡数据来训练seq2seq闲聊模型,但直接使用效果很差,而且还容易生成骂人的答复。
| 问题 | 答案 |
|---|---|
| 不是 | 那是什么? |
| 怎么了 | 我很难过,安慰我~ |
| 我还喜欢她,怎么办 | 我帮你告诉她?发短信还是打电话? |
| 短信 | 嗯嗯。我也相信 |
| 这么假 | 三鹿奶粉也假,不一样的卖啊 |
| 许兵是谁 | 是我善良可爱的主人的老公啊 |
| 许兵到底是谁 | 不要凶我~应该大概也许是叶祺吧~ |
| 尼玛,许兵到底是谁 | 我。。。我不会告诉你我是小澜的!(^V^) |
| 那你有男朋友么 | 没有呢,我只要主人一个人疼爱我嘛。。 |
| 那你在哪 | 我无聊 |
| 你妈是谁 | 我妈妈是世界上最温柔的主人你啊 |
| 你大爷的 | RuoRuo弱爆了。尤其是她现在冻的更憨了 |
| 呵呵 | 呵呵你大爷 |
| 呵呵 | 呵你妹,你呵呵了我要怎么回答你。哈哈? |
| 天王盖地虎 | 宝塔镇妖河。 |
| 小通 | 臣在 |
| 在监考,你在干么 | 在边打dota边想悦悦。 |
选择Matcher模型
在具体清洗流程开始前,还需要确定使用什么模型作为DPF中的Matcher模型。 对于qa对话数据,我们发现dual encoder模型是一个好的选择。dual encoder首先利用RNN把问题和答案都向量化,然后以这两个向量的匹配程度来说明这个问答对的匹配程度。
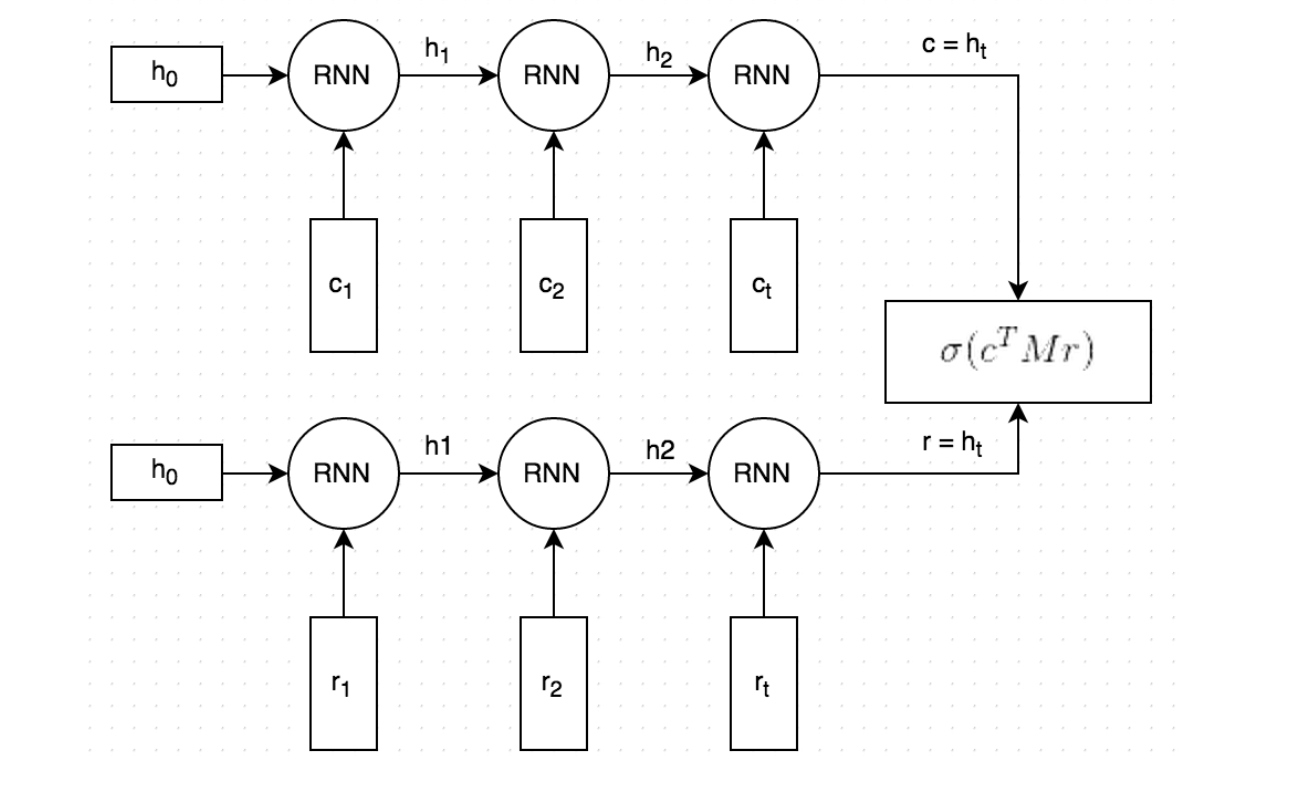
接下来说明清洗小黄鸡对话数据的具体流程。
清洗流程
训练Matcher1.0,清除噪音数据
在训练Match1.0时,我们把所有的小黄鸡qa对作为正样本,然后随机抽取一些q和其他的a生成相同数量的负样本。从预测准确度来看,Match1.0在训练集上只能到0.75左右,在测试集上大概0.65,很差。
把训练好的Match1.0用于预测其训练集中的所有正样本(也即原始的小黄鸡qa对),并按照预测的匹配概率对qa对进行排序。然后把匹配概率低于某个阈值的qa对全部删掉(如果删除过多,可以设置一个删除的最高比例)。比如在这里我们设置了0.5的匹配阈值。
训练Matcher1.1,进一步清除噪音数据
以上一步清洗后的数据作为正样本,随机产生等量的负样本。利用这些正负样本训练Matcher1.1。把训练好的Match1.1用于预测其训练集中的所有正样本,并按照预测的匹配概率对qa对进行排序。然后把匹配概率低于某个阈值的qa对全部删掉(如果删除过多,可以设置一个删除的最高比例)。这个流程跟上面一样,但这里的匹配阈值可以设置得更高,比如0.6,因为此时训练数据和模型都比Matcher1.0更好了。Match1.1在训练集上的准确度能到0.82左右,在测试集上大概0.7。
训练Matcher1.2 –> Matcher1.x,逐步迭代清除噪音数据
和上面的流程一致,对上面清洗好的数据做进一步的清洗。此时的匹配阈值可以再高点,比如0.7。Match1.2在训练集上的准确度能到0.89左右,在测试集上大概0.76。
这个循环继续,直到Matcher1.x在训练集上的准确度达到预设值(比如0.98),或者被清除的数据量低于预设数量,或者迭代次数达到预设值(比如10次)。在这个过程中,匹配阈值可以设置得越来越高,最高可以到0.9甚至0.95。因为后面模型的精度逐渐变高,所以阈值更高也不会删除很多数据(应该让被清除的数据量逐渐降低)。在小黄鸡数据上,Matcher1.8在训练集上的准确度超过了0.98。它的训练集里的正样本只有清洗后剩下的7w+条qa对。
迭代到这步,其实可以像之前的迭代那样对训练数据进行清洗,然后把剩下的数据作为我们最终的数据结束整个清洗过程。但很多时候我们希望能从已被清洗的数据中再找回一些靠谱的数据。毕竟早期用于清洗的模型本身也并不是那么靠谱。
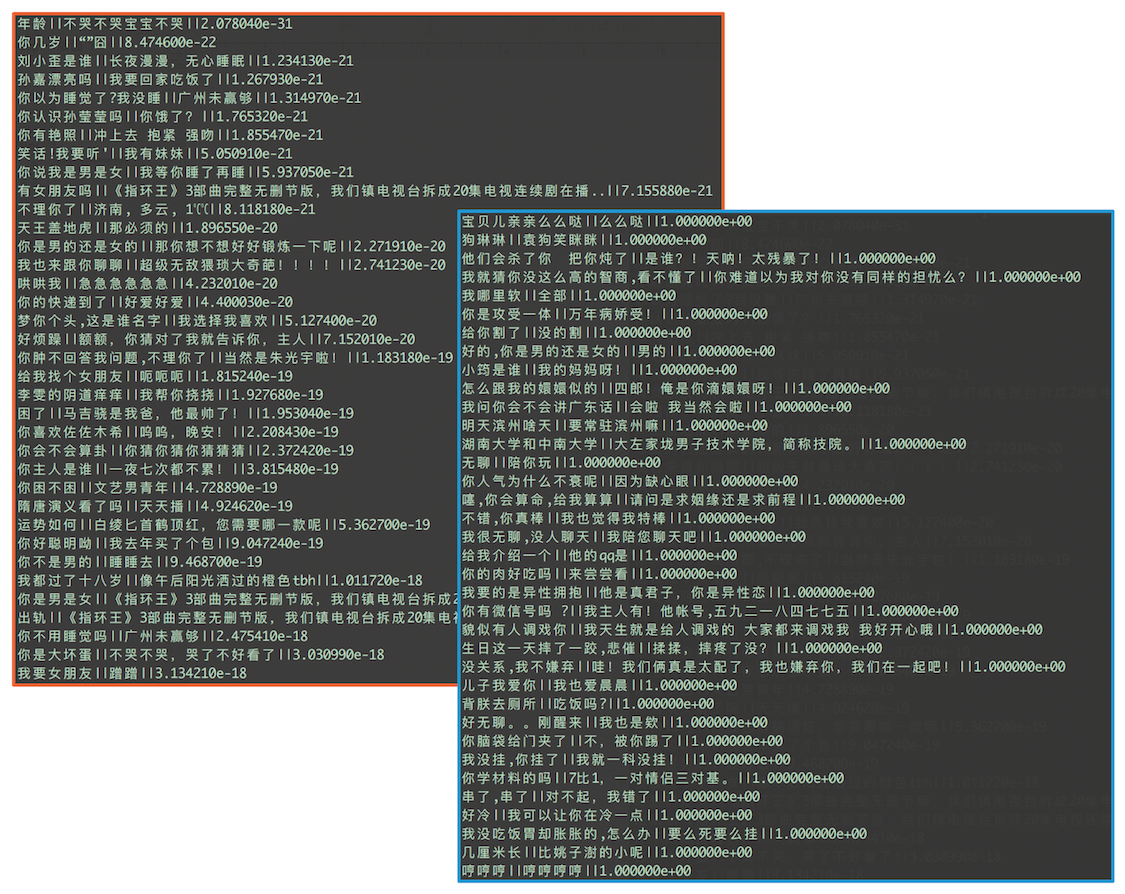
所以我们可以把Match1.8用于最初的全量数据上,预测它们的匹配概率。这就是框架图里第一列到第二列的连接线。和之前的步骤一样,按匹配概率排序,把低于设定阈值的样本去掉。小黄鸡里如果我们设置阈值为0.9,清洗后可以剩下11w+的qa对。下图中展示了一些匹配概率最低(左上角红框)和最高(右下角蓝框)的样本。每行代表一个样本,格式为问题||答案||匹配概率值。可以看出区分度还是很明显的。
清洗后的结果数据可以作为最终结果返回,也可以进一步进行提纯,把它作为Matcher2.1的训练集,继续迭代……
实际运行时,我们在小黄鸡数据上跑到Matcher1.8就结束了,在微博数据上我们跑到了Matcher3.5,训练集上的准确度达到0.981。
DPF的清洗过程虽然无需人工干预,但每步迭代都需要重新训练模型,在数据量大时整个过程还是很耗时的。一个降低训练时间的方法是每次训练新模型时,把其参数初始化为前一个模型的训练结果。
Seq2seq+Attention模型结果
我们把上面Matcher1.8清洗获得的7.1w+小黄鸡qa数据作为训练集,以单字模式训练seq2seq+attention对话生成模型。
下面是一些模型结果(我们对基本模型做了一些改进,具体请见我们之后的文章)。其中Q表示问题,A表示使用beam search产生的topN答案,A后面的数字表示序号,比如A2表示排名第二的结果。
注:有些候选结果被某些后处理步骤过滤掉了。
Q: 我不想学习肿么办
A1: 加油加油
A2: 好好学习
A3: 考什么
A4: 没事,以后我养你
Q: 感冒了,难受死了
A1: 快去医院
A2: 怀里
A3: 我吃你
A4: 睡觉吧
A5: 多喝点热水
A6: 没事,有你的
A7: 快去医院 不要怕
A8: 快去医院 不要紧,赶紧去道歉
A12: 没事,有我陪你的
Q: 谢谢你爱我
A1: 我也爱你
A2: 讨厌
A3: 大宝贝
A4: 爱你的!!
A5: 主人我爱你
A6: 亲爱的主人
Q: 是先有鸡还是先有蛋
A1: 好难的问题
A2: 先有卵
A3: 可以吃你
A4: 无聊的人
A5: 可能是女的
A6: 去问问上帝就知道了
A7: 根据相关法律法规,呵呵
Q: 手机没电了咋办
A1: 好好吃
A2: 怎么行
A3: 那就快去睡吧
A4: 没事,有我陪你
A5: 好好复习吧
A6: 好好吃不起
A7: 那你想怎么办
最后做个广告,爱因互动在招NLP和机器学习算法工程师,欢迎感兴趣的同学自荐~。