Wit.ai[注:要梯子]是Facebook收购的一家AI公司,他们的主要产品是一个帮助制造chatbot的平台:Bot Engine。Chatbot开发者可以通过bot engine提供的网页工具和API接口比较方便地构建具有某种特定功能的chatbot,比如酒店预订、订餐、打车,甚至是找对象等等。
它本质上还是利用检索技术完成对话的,也就是需要开发者维护很多问答对。但是内部又使用了很多机器学习技术来使得问答对的维护比较灵活方便,而且系统对于问答对具有比较好的泛化性。下图是开发者的网页截图。
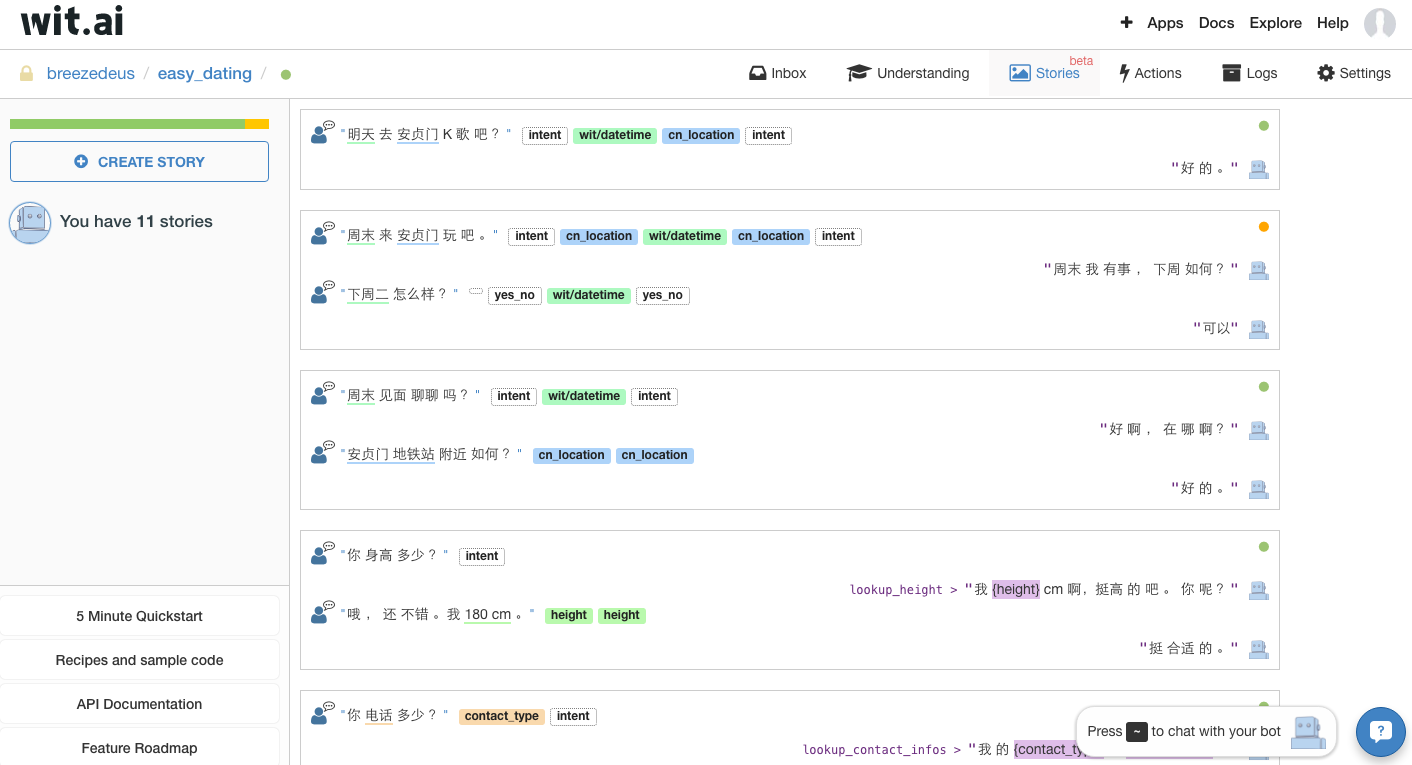
我在之前的文章“Google的智能问答技术”中介绍了Google的Gmail和Allo已经在使用深度学习RNN模型来自动产生问题的答案,而wit.ai却还在用检索式的方式,wit.ai是不是很low?嗯,是挺low的。但是目前也只能用这种low的检索方式来做垂直领域具有特定功能的chatbot。
Gmail和Allo里的smart reply针对的场景是泛聊,也就是唠嗑,而wit.ai针对的场景主要是完成垂直领域的特定功能。唠嗑的前后连贯性不需要那么强,而让用户顺利完成某件事时却依赖很多背景信息。比如订披萨时你需要告诉chatbot要订多大尺寸,什么口味,要不要加料,还要告诉它什么时间送到什么地方由谁接收等等。这么多信息是通过与chatbot的多次交互不断收集来的。
目前,RNN等深度学习模型并不善于收集长期的背景信息!
当然,从拥有的数据量上来看一般的开发者也是没法和Google比的。其实,我相信Google的聊天应用Allo里也同样大量用到了检索式方法来产生特定功能问题的答案。
检索式chatbots
目前,基于检索模式的bot构建系统基本都遵循一个假设:
用户在发起一个提问时都有一个明确的意图。
下图给出了chatbot完成一次请求时的大致流程和一个示例。系统分析用户的输入,预估用户的意图,以及识别输入中包含的实体,这些实体是在达成意图时需要的。而bot开发者需要做的事就是为一些用户输入定义好它们对应的意图和包含的实体,以及为了达成这些意图需要执行的动作(见图中的3个蓝色实线块),这样系统可以依据用户给定的这些数据训练模型以便在一般情况下预测用户输入对应的意图和识别包含的实体。
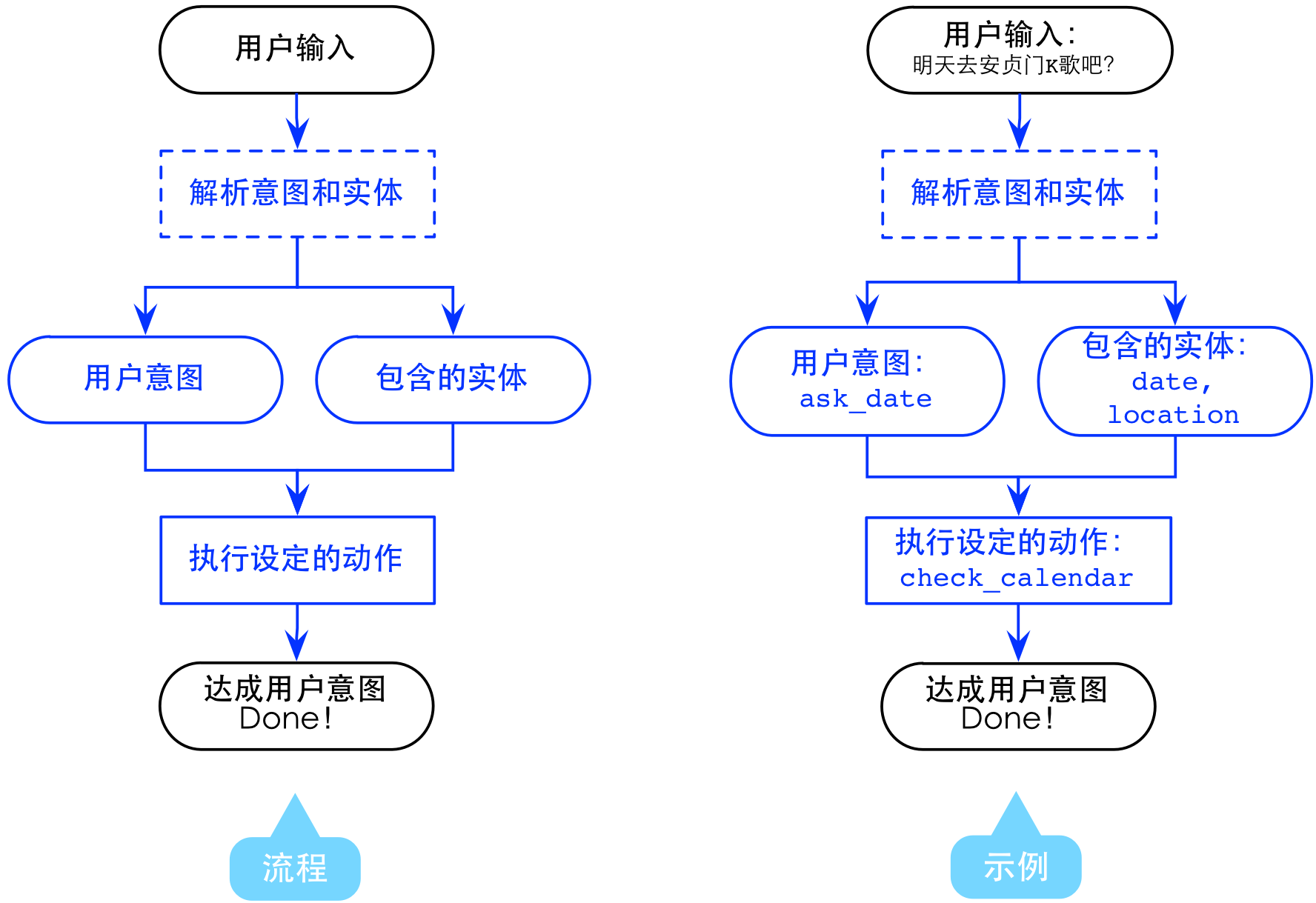
Wit.ai基本遵循上面的流程。下面通过构建找对象chatbot来介绍wit.ai的整体思路以及里面的各种关键概念。先介绍关键概念。
Wit.ai
实体(Entities)
实体(Entities)就是描述事物的一些概念,可以认为对应着知识图谱里的结点。这些概念可以是比较具体的,也可以是比较抽象的。比如在找对象聊天中,实体可以是身高、学历、联系方式,也可以是对话意图(Intent)等抽象概念。Wit.ai并没有把意图作为一个特别的实体,它和其他实体是一样的,在每个对话流程里可有可无。
Wit.ai里把实体分为三大类:
- 特性(Trait):需要利用整个句子而不是某些特定词语来获得的实体,例如下图中的”intent”、”yes_no”。特性实体的取值是在给定集合中的,如”yes_no”这个特性实体取值为”yes”和”no”。
- 关键词(Keywords):利用某些特定词语就可以获得的实体,例如下图中的”height”、”education”等。关键词实体的取值是在给定集合中的,如”education”这个关键词实体可以取值为“中专”、“大专”、“本科”、“硕士”和“博士”。
- 自由文本(Free-text):自由文本实体和关键词实体类似,也是通过语句中局部的表达词语就可以确认的,不同的是它的取值不限于某个集合而是可以很灵活。
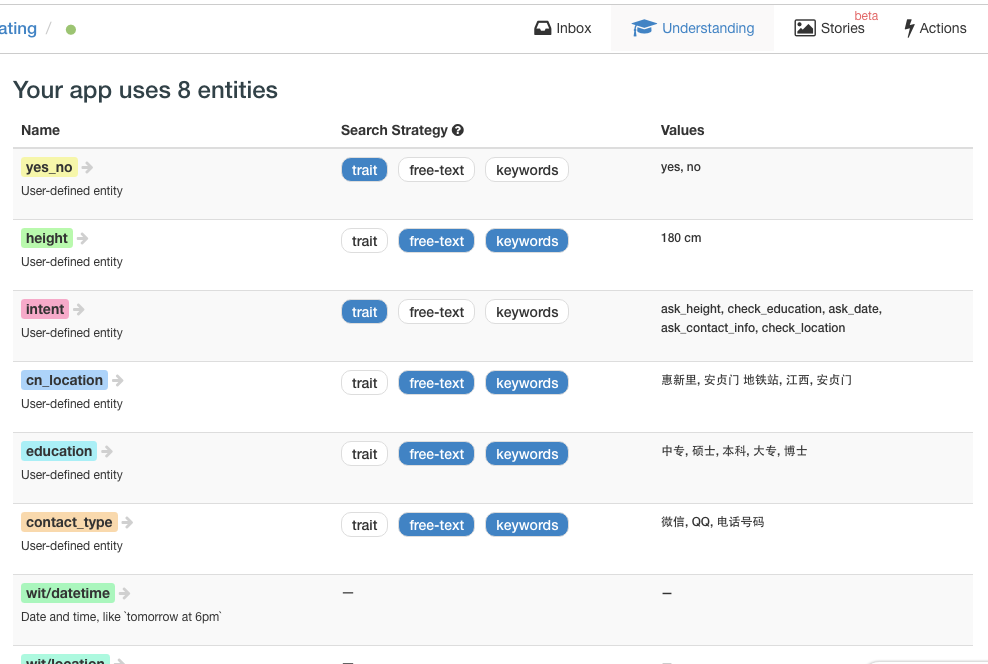
特性实体与其他两种实体不兼容,也就是一个实体如果是特性实体,那它就不能是其他两种实体。而关键词实体与自由文本实体是兼容的,也就是一个实体可以既是关键词实体,也可以是自由文本实体。目前,wit.ai中的实体之间并未引入层级关系。
系统自带了一些实体(名字为“wit/xxxx”)可供bot开发者使用,比如wit/datetime是系统定义的时间实体。
Bot开发者可以通过wit.ai里的“Understanding”页面对一些语句标注里面包含的实体。系统会利用这些标注的数据来训练模型识别用户输入语句中包含的实体。
动作(Actions)
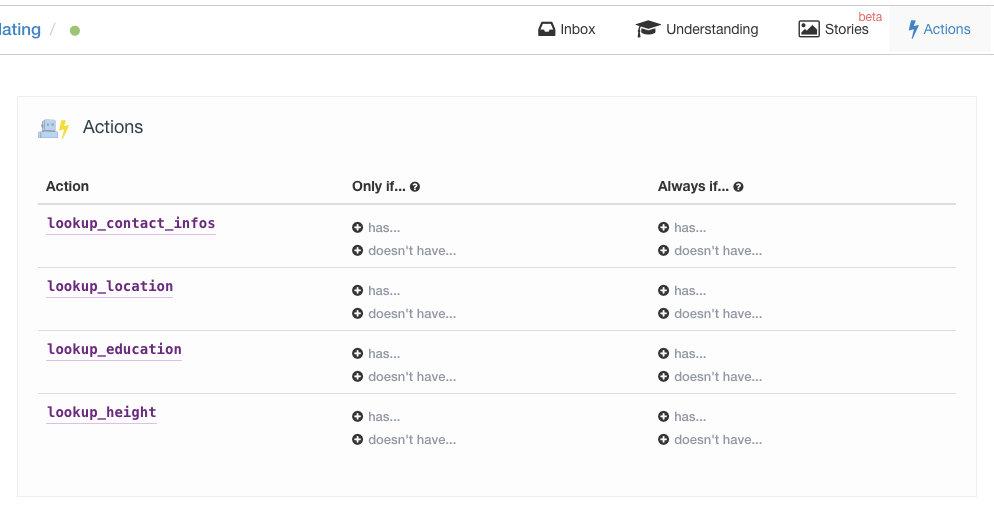
动作(Actions)指的是用户自己定义的一些函数。这些函数在某些特定场景触发而被调用。这些函数是在本地代码中定义的,在wit.ai上只是一种声明。
每个动作可以包含一些输入参数,这些输入参数可以分为两类,一类是强制的(required),另一类是可选的(optional)。在调用此动作时,必须传入所有的强制参数,而可选参数则可有可无。下图中表明我定义了4个动作,分别用于查询联系方式、位置、学历和身高,都没有强制输入参数。
故事(Stories)
一个故事(Story)相当于完成用户一次需求的整个对话session。通常一个故事对应着一个意图。下图中展现了一个求约会的故事。
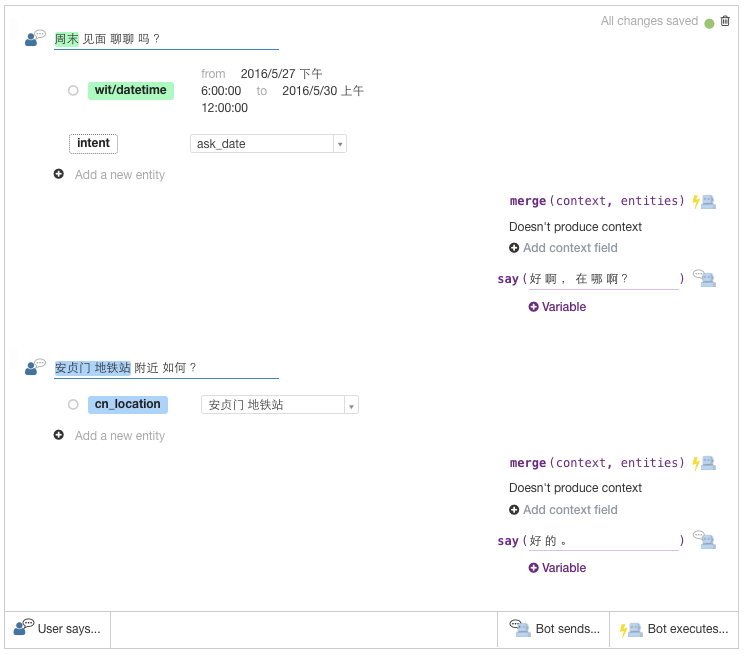
故事的开始是开发者设定用户端的输入语句,比如“周末 见面 聊聊 吗 ?”,wit.ai目前对中文的支持不够好,所以在输入语句时可以直接分好词。Wit.ai会自动识别里面的实体,如果有些实体识别不对,开发者可以很方便地进行修改。之后bot会依据用户端的输入执行对应的动作。系统默认会有个merge动作,它的实现也是本地的,通常可以用它来把输入端识别出的实体传给bot端。开发者也可以在merge后执行自己定义的动作。在执行动作后bot端会给出答复,如“好 啊 , 在 哪 啊 ?”。之后用户端接着输入,继续这个循环操作。
开发者可以为同一个意图设定多个故事,下图中显示我为求约会这个意图设定了三个故事。通常一个故事设定为达成某一意图的一条路径(path)。比如约会需要有时间和地点两个实体,那获取这两个实体的不同方式就可以设定为不同故事。
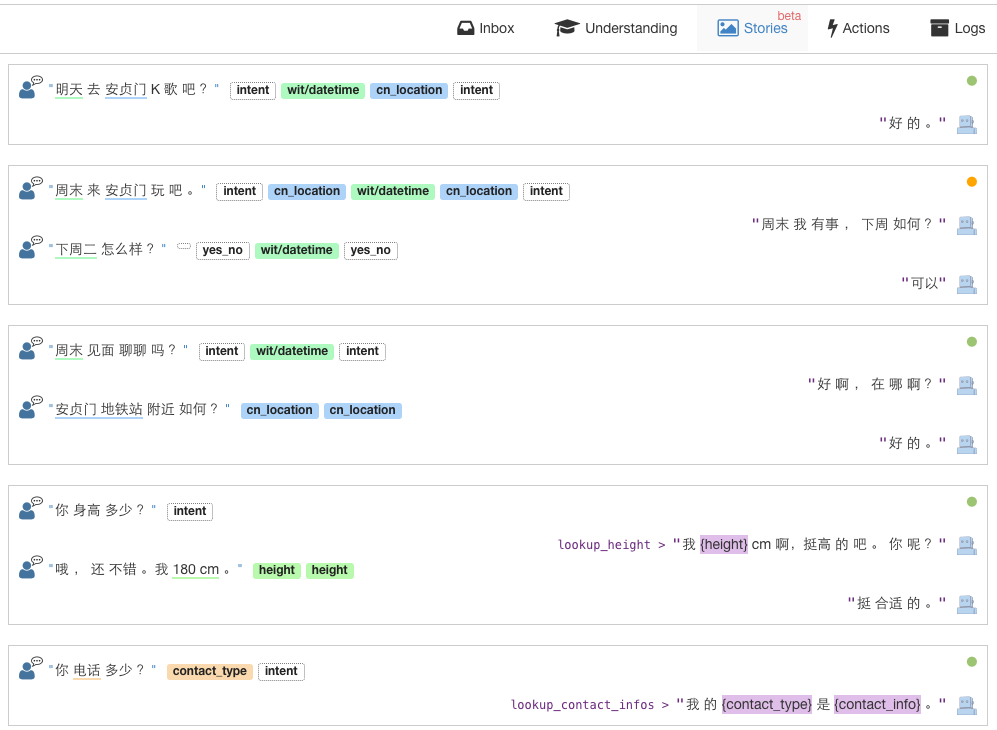
但也不需要为所有路径都创建一个故事,wit.ai可以使用已创建的故事来自动生成新的路径以完成某个意图。
Wit.ai会自动检查不同故事之间的兼容性。如果开发者调整(增删改)了某个故事,系统会自动全部重新训练,这会影响到所有故事。
故事体现了wit.ai系统的整体思路。里面涉及到两个最重要的概念:实体和动作。在其他bot创建系统中(如Api.ai,LUIS),通常会把意图和其他实体分别对待,而在wit.ai中意图和其他实体并无差别。
其他
Wit.ai会记录所有的调用日志,bot开发者可以查看log数据,然后把有问题的问答提取出来,加入到已有的训练语料中。
虽然wit.ai的bot engine还有很多bug,但他们改进的速度也很快,值得期待。对天朝人民来说最悲催的是它被墙了。。。
关于wit.ai就介绍这么多,建议对chatbots感兴趣的同学自己动手玩玩,这比看多少文档都强。除了wit.ai,还有很多类似的网站,比如Api.ai和LUIS。Api.ai也是个创业公司,LUIS是微软推出的。他们的整体思路和大部分细节都和wit.ai差不多,下面只说几点不同的地方。
Api.ai的特别之处
和wit.ai一样,api.ai在意图构建时可以触发动作(action)。此action可以要求一些(强制或可选的)输入参数。Api.ai为每个强制输入参数丢失时设定触发一个新的action,利用此action来获取此输入参数。在多个强制参数丢失时,也可以定义各参数对应的action的触发顺序。微软的LUIS也是这么做的。
只有在所有强制输入参数都获取到时此意图绑定的那个action才会被触发。
LUIS的特别之处
目前,LUIS的一些特别之处:
- 最多支持10个entities。Entity可以设定子entity,一个entity可以定义最多10个子entities。
- 使用逻辑回归模型来预测intent,CRFs来识别entities。
- 利用active learning来产生一些需要用户手动标注的语句,使得把标注后的语句加入到原始训练预料里可以最大限度地优化现有模型。
- 对中文的支持较好。
Why Chatbots Now?
我一直在想一个问题,现在检索系统或者专家系统相对于半个世纪前有什么变化?半个世纪前chatbots没搞成,现在搞成的可能性有多大呢?除了机器学习模型和计算机的计算能力相对于半个世纪前强很多,现在利用互联网数据获取比半个世纪前更容易了,我想不出有其他差异。这些差异会带来chatbots质的变化吗?
当然,以深度学习为代表的产生式模型现在已经取得比较大的进步,已经可以为一些简单的问题自动产生答复了,而且还在快速的发展。它们会给chatbots带来质的变化吗?