微软研究者最近发表了论文“End-to-end LSTM-based dialog control optimized with supervised and reinforcement learning”,论文里提出了利用LSTM构建半检索式聊天系统的一般框架。这是流程图,下面我以用户输入“Call Jason Williams”为例具体说明每步都在做什么。
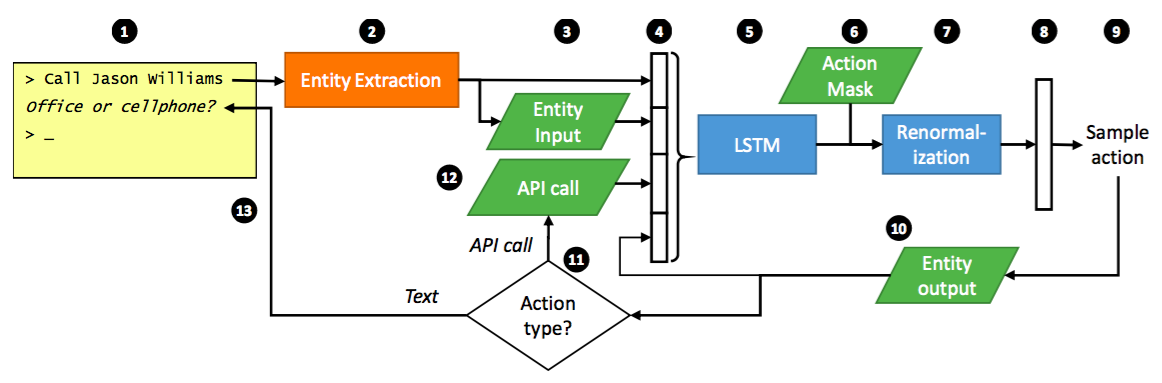
- 用户输入。输入可以是文本或者语音。这个例子中用户的输入是“Call Jason Williams”。
- 抽取用户输入中包含的实体。Bot平台一般会提供实体抽取的功能,开发者不需要自己实现了。抽取的实体可以是bot平台默认提供的,也可以是开发者自己加的。这个例子中可以抽取出类型为
<name>的实体,<name>的值为“Jason Williams”。 - 把上一步抽取出的实体对应到开发者应用的数据。此例中会把“Jason Williams”对应到存储联系方式数据表中的一行或多行(多人同名)。这些对应出来的信息也可以在后续流程中使用。
- 把4类数据合成为LSTM模型的输入向量。其中
- 第1类数据是“步骤2”中抽取的实体类别。比如总共有2个实体类别:
<name>和<phonetype>。<phonetype>代表的是电话号码的类型,取值为”office”或”mobile”。而此例子抽取到<name>实体,那么对应的特征向量为[1, 0](One-hot表达方式)。 - 第2类数据来自于“步骤3”中获得的对应数据。这些数据可以根据开发者的设定产生相应的特征向量。此例子中“Jason Williams”对应到一个联系人,这个人有2种电话号码。那么可以把输出的特征向量设定为
[user_id, 2],其中user_id是联系人id。 - 第3类和第4类数据来自于上一个循环的“步骤9和12”。具体见“步骤9和12”。
- 第1类数据是“步骤2”中抽取的实体类别。比如总共有2个实体类别:
- 利用LSTM预测各回复对应的概率值。回复主要包括两类:第一类是包含了实体类别的输出答复,如“Do you want to call
<name>?” 第二类是API的动作函数,如“placePhoneCall(<name>)”。LSTM返回在当前场景下使用各回复的概率值。 - 根据开发者的代码逻辑选定回复过滤器。
- 依据选定的过滤器,把不合适的回复过滤掉,并对结果进行概率归一化。例如在还没获取到具体的电话号码时就没法拨打电话,所以需要过滤掉“placePhoneCall(
)”。然后把过滤后的回复概率值重新归一化,使概率值总和为1。这就产生了下一步中的回复分布。 - 过滤后的回复概率值重新归一化后,获得此步骤里的回复分布。
-
从回复分布中选取一个回复。从分布中抽取一个样本有两种常用的方法。第一种是直接选概率值最大的样本,另一种是按概率分布进行抽样。具体使用哪种依赖于具体应用。第一种方法的结果是确定的,比较可控;第二种方法的结果有随机选,更加灵活但可控性也更差。
选出的回复有两个用途。第一个用途是此回复会作为特征传给下一个循环的“步骤4”,特征可以是此回复的id,或者由回复内容产生的特征;第二个用途是传给下一步。
- 替换回复里的实体类别为对应的取值。比如上一步传过来的回复可能是“
<phonetype>or<phonetype>?”,替换后就变成了“office or cellphone?”。 - 判断回复的类别。如果回复类别是输出答复,那就直接通过“步骤13”返回给用户;如果是API动作函数,那就走“步骤12”。
- 调用开发者设定的动作函数。其返回结果作为特征传给下一个循环的“步骤4”。
- 输出答复给用户。此例中答复为“office or cellphone?”。
再重复一遍流程图,方便大家对比着看。