Siri的开发团队从苹果离职后开发了Viv,一个bot创建平台。Viv还没正式发布,只是在今年5月9日的TechCrunch Disrupt(演讲视频)大会上show off了一下,以下是系统截图。
关于Viv使用到的技术,可参考的资料很有限,以下信息主要来自Viv在2014年底申请的一项专利:基于第三方开发者的动态演化认知架构系统。没兴趣看几十页专利的同学也可以看看Quora上的讨论。
介绍
Viv中主要包含了两种对象:概念对象(Concept Object)和动作对象(Action Object),其中概念对象指的就是实体,而动作对象就是执行的动作。
概念对象之间定义了两种关系:扩展(extension),相当于“is a”的关系,比如“跑步鞋”概念对象扩展自“鞋”概念对象;属性(property),相当于“has a”的关系,比如“跑步鞋”概念对象有属性“尺码”概念对象。
动作接收一些概念对象,然后产出一些新的概念对象,类似于函数有输入和输出。动作接收的概念对象包含了两类,一类是必须要有的,没有动作就没法执行;另一类是可选的,可有可无。这个设定和Wit.ai、Api.ai中的类似,很好理解。
相对于Wit.ai和Api.ai来说,Viv更加灵活,或者说更加“智能”。以概念和动作对象为结点,Viv构建了规模庞大的有向网络图。概念结点到动作结点的边表示此动作以此概念为输入参数,而动作结点到概念结点的边表示此动作的输出中包含了此概念。如果两个概念结点存在扩展或者属性关系,那么它们之间也会存在有向边。随着开发者不断把新的概念和动作对象加入到Viv系统,这个网络图会逐渐延伸,越来越大。借助于Viv的动态演化认知架构系统,Viv能做的事会随着网络图的增大而指数增长。
产生答复的具体步骤
Viv把自己的系统称为动态演化认知架构系统(Dynamically Evolving Cognitive Architecture System,简称DECAS),大意是说随着越来越多的开发者接入Viv,Viv能做的事不是呈线性增长而是呈指数增长。他们的目标是让Viv存在于人类生活的各个角落。
以下是Viv在接收到用户输入时的操作步骤。
一、从用户输入中解析出意图
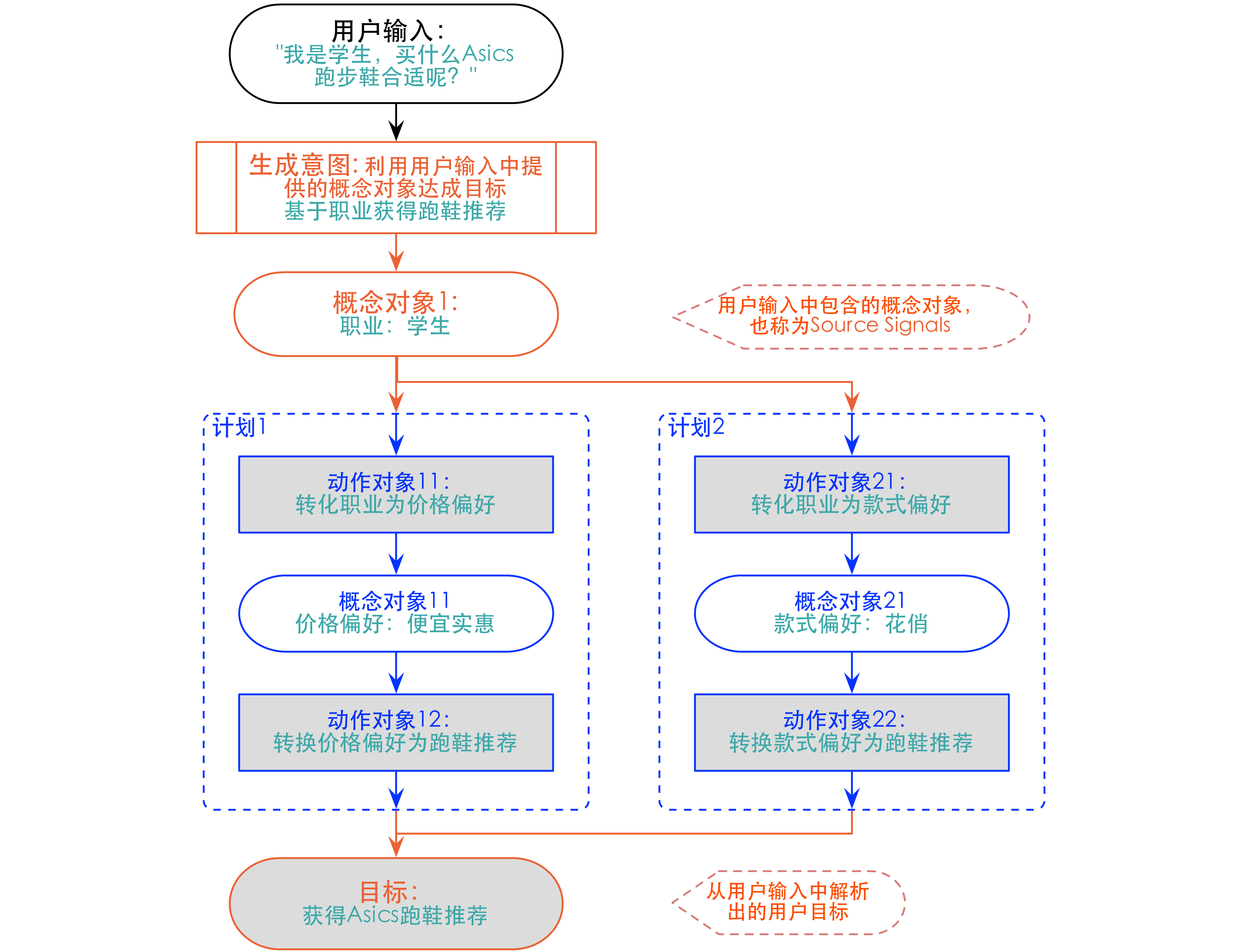
Viv首先从用户输入中解析出用户的意图(Intent)。意图由目标(Goal)和概念对象组成,其中目标只有一个,而概念对象则包含了从用户输入中解析出的所有概念对象,可以是多个。比如用户输入“我是学生,买什么Asics跑步鞋合适呢?”,Viv解析出的意图可能如下图:

此意图只包含了一个“职业”概念对象,而它包含的目标是“获得Asics跑步鞋推荐”。意图里的概念对象和目标是需要开发者提前定义好的,但由它们组合而成的意图并不需要提前定义。
Viv做的事,是利用意图中的概念对象,通过执行一系列开发者定义的动作,最终达成意图中的目标。
二、利用意图中的概念对象达成意图中的目标:DECAS的核心技术
在解析完意图后,Viv需要决定如何利用意图中的概念对象来达成意图中的目标。如果执行一个动作就可以达成目标,那当然直接执行下这个动作就搞定了。但显然实际情况复杂得多,用户可不知道开发者定义了什么动作。
比如上面推荐跑鞋的例子,如果开发者定义了这两个动作:1) transform_occupation_to_price,按照用户职业推断他/她买鞋的价格偏好;2) rec_shoes_based_on_price,依据用户的价格偏好来给他/她推荐Asics跑鞋。这两个动作单独都没法实现从“职业”概念对象到跑步鞋推荐的目标。但把它们串联起来就可以实现这个目标了。
DECAS的核心,就是如何串联起不同的动作来达成目标。放在之前提到的概念和动作组成的网络图里面说,其实就是找意图中概念结点到意图中目标结点的各种连通路径。(虽然Viv没有具体说,但目标结点应该也是一种概念结点。)Viv把一条路径称为一个计划(Plan)。计划中使用到的动作可以跨应用,可以来自于不同开发者设定的动作。
下图中给出了达成跑鞋推荐的两个计划,其中计划1就是串联了我们上面说的两个动作,而计划2则是串联了transform_occupation_to_type和 rec_shoes_based_on_type这两个动作。开发者可以为每个计划设定一个价值函数,DECAS则只需要选择价值最高的topN计划具体执行即可。当然,DECAS可能做得更复杂,比如依据用户反馈实时调整计划。
如果一个计划包含的动作所需的必须输入概念对象缺失,那么就需要与用户进行多次交互以收集缺失概念对象的值。
本文末尾附了Viv官方给出的一个实际例子,感兴趣的同学可以仔细看看。
总结下,Viv是以动作为核心的网络系统。 它首先让开发者定义对应领域的概念对象和动作对象,然后自动生成计划(网络图中找两个结点间的路径), 利用用户输入中的概念对象完成用户的目标。相对于Api.ai只能使用开发者设定的意图来完成已知的需求,Viv能做的事可以超出开发者设定的场景,在联合不同开发者定义的概念和动作对象后可以执行一些不在开发者设定范围内的意图。随着越来越多开发者接入Viv,它能做的事会指数增长。
Viv组合的是动作,而Api.ai组合的是粒度更大的意图。所以Api.ai更可控,而Viv更加智能。
痛点
开发者如何维护自己的应用
我还没看到有资料里对开发者如何维护自己的应用说的比较清楚的。开发者当然要维护自己的概念和动作对象,但机器人的回复在哪维护,怎么维护,都不清楚。Viv好像开发了很多辅助工具帮助开发者管理自己的应用,但具体都有什么工具暂时还不清楚。
越灵活的系统,对维护者的要求就越高,维护成本也会越高,除非系统失控也无所谓。像Viv以动作为基本组合元素这种灵活的架构,平台之外的开发者端所需要的维护肯定也不少。应用中的很多事可能在Viv平台没法做,需要放到开发者自己的平台上实现。
如何使用背景信息
这个问题任何对话系统都有,但Api.ai提供了一种不灵活但简单的处理方法——在每个意图中开发者可以设定触发这个意图的背景,以及此意图执行后会产生什么新的背景。
Viv如何做呢?
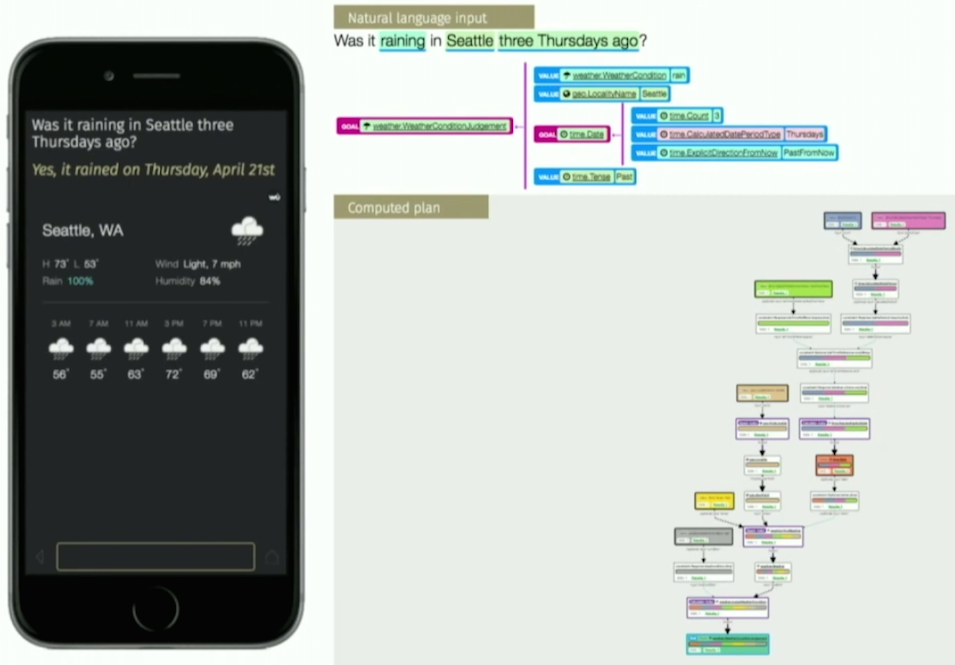
对Viv感兴趣的同学可以仔细看看这个Viv介绍视频。下面是Viv官方给出的一个示例,从中能感受到其解析过程的精细性和复杂性。

说了这么多,其实都是管中窥豹。Viv已经秘密研发了好几年,其隐忍值得佩服!期待Viv的发布。希望Viv能给bot带来更多新的工程思路。
欢迎大家关注微信公众号ChatbotsChina,获取bot相关的更多信息。
